Abstract
Arabic handwritten text recognition is a challenging OCR problem because Arabic script is cursive, characters change shape depending on their position in a word, and handwriting styles vary significantly between writers.
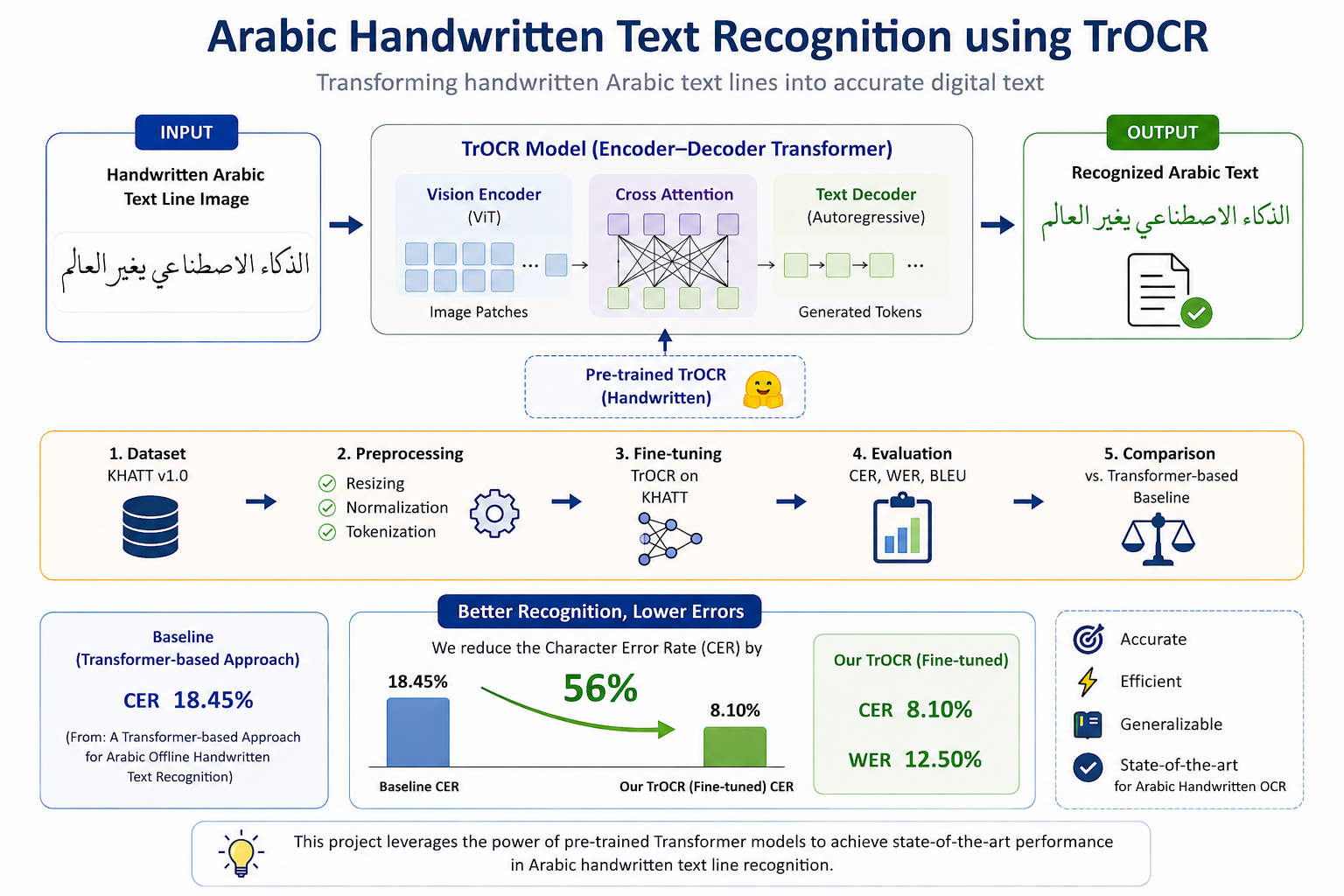
This project fine-tunes TrOCR, a Transformer-based encoder-decoder OCR model, on the KHATT v1.0 Arabic handwritten text-line dataset.
Our system takes an image of a handwritten Arabic text line as input and outputs the corresponding digital Arabic text. The fine-tuned TrOCR model achieved a CER of 8.10% and a WER of 12.50%, showing a strong improvement compared with the cross-attention Arabic handwritten recognition baseline.
Introduction
Optical Character Recognition (OCR) converts images of text into machine-readable text. While OCR systems have achieved strong performance for printed Latin text, Arabic handwritten OCR remains difficult because Arabic is cursive and highly variable.
Traditional OCR systems usually combine CNNs for visual feature extraction, RNNs for sequence modeling, and CTC for alignment. These pipelines are effective but complex.
TrOCR simplifies the pipeline by using a Vision Transformer encoder and a Transformer decoder in a fully end-to-end architecture.
In this project, we investigate whether a large pre-trained Transformer OCR model can transfer effectively to Arabic handwritten text recognition.
Approach
System Input and Output
The input to the system is a single handwritten Arabic text-line image. The output is the corresponding digital Arabic text transcription.
TrOCR Architecture
TrOCR is an encoder-decoder Transformer OCR model. The encoder processes the image and extracts visual features, while the decoder generates the output text token by token.
Arabic Decoder Modification
Since the original TrOCR decoder is mainly designed for English language modeling, we modified the decoder to better support Arabic text generation by initializing it with bert-base-arabic.
This modification helps the model better understand Arabic vocabulary, linguistic structure, and contextual relationships during autoregressive text generation. The goal of this change is to improve recognition quality for Arabic handwritten text and reduce character-level prediction errors.
Implementation
We used Python, PyTorch, and the Hugging Face Transformers library. Existing TrOCR model weights were used as initialization, while preprocessing, fine-tuning, evaluation, and metric computation were implemented for this project.
Challenges
- Arabic writing direction: Arabic is written from right to left.
- Handwriting variability: KHATT contains many different writing styles.
- Character ambiguity: Many Arabic letters differ only by dots.
- Evaluation fairness: CER is used as the primary evaluation metric.
Experiments and Results
Dataset
We use KHATT v1.0, an Arabic offline handwritten text-line dataset containing samples from many writers.
Evaluation Metrics
| Metric | Description | Direction |
|---|---|---|
| CER | Character-level edit distance | Lower is better |
| WER | Word-level edit distance | Lower is better |
| BLEU | Sequence similarity metric | Higher is better |
Quantitative Results
| Model | Dataset | CER ↓ | WER ↓ |
|---|---|---|---|
| Cross-Attention Arabic HTR Baseline | KHATT | 18.45% | — |
| Fine-tuned TrOCR + Arabic Decoder | KHATT v1.0 | 8.10% | 12.50% |
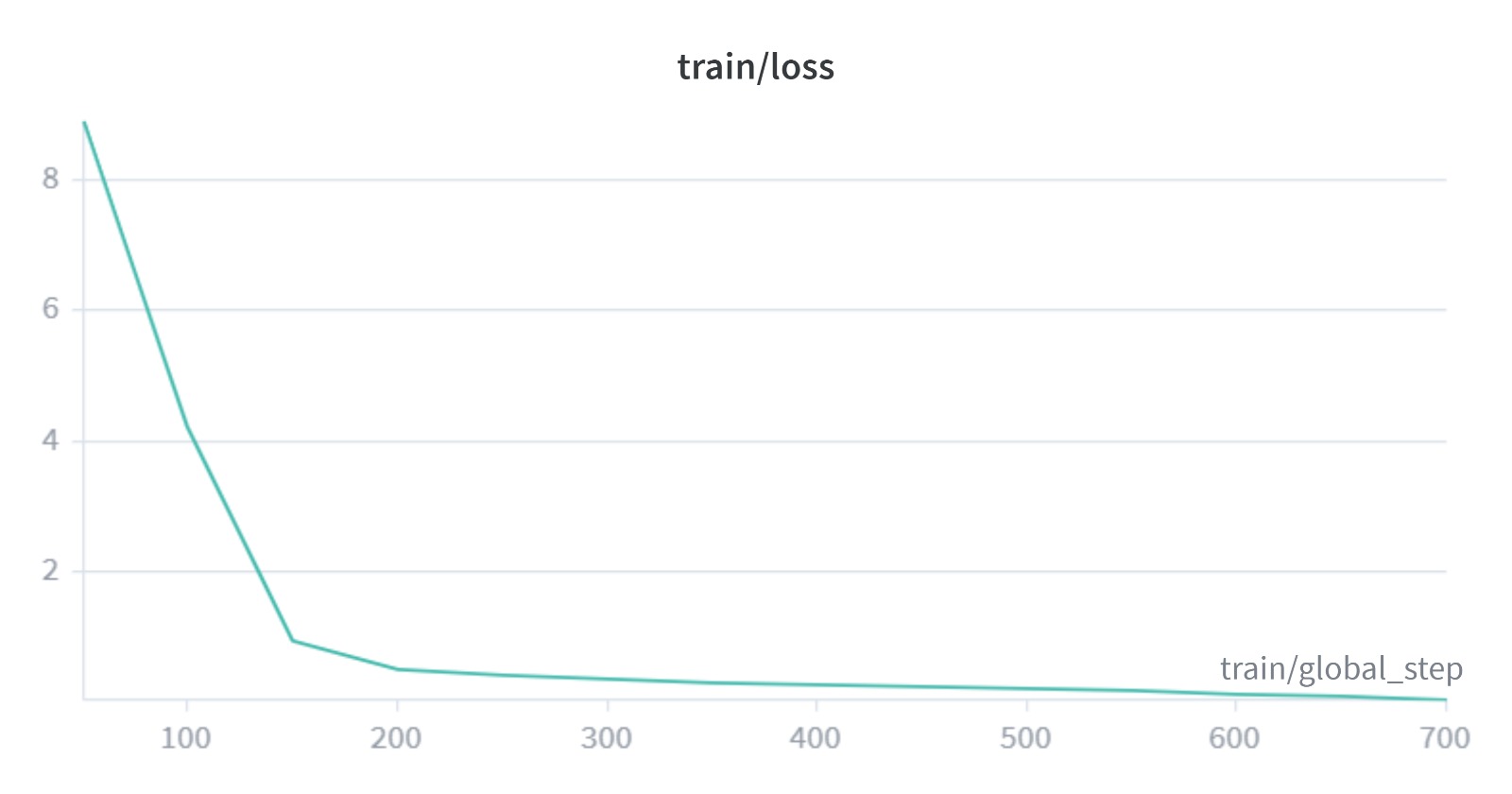
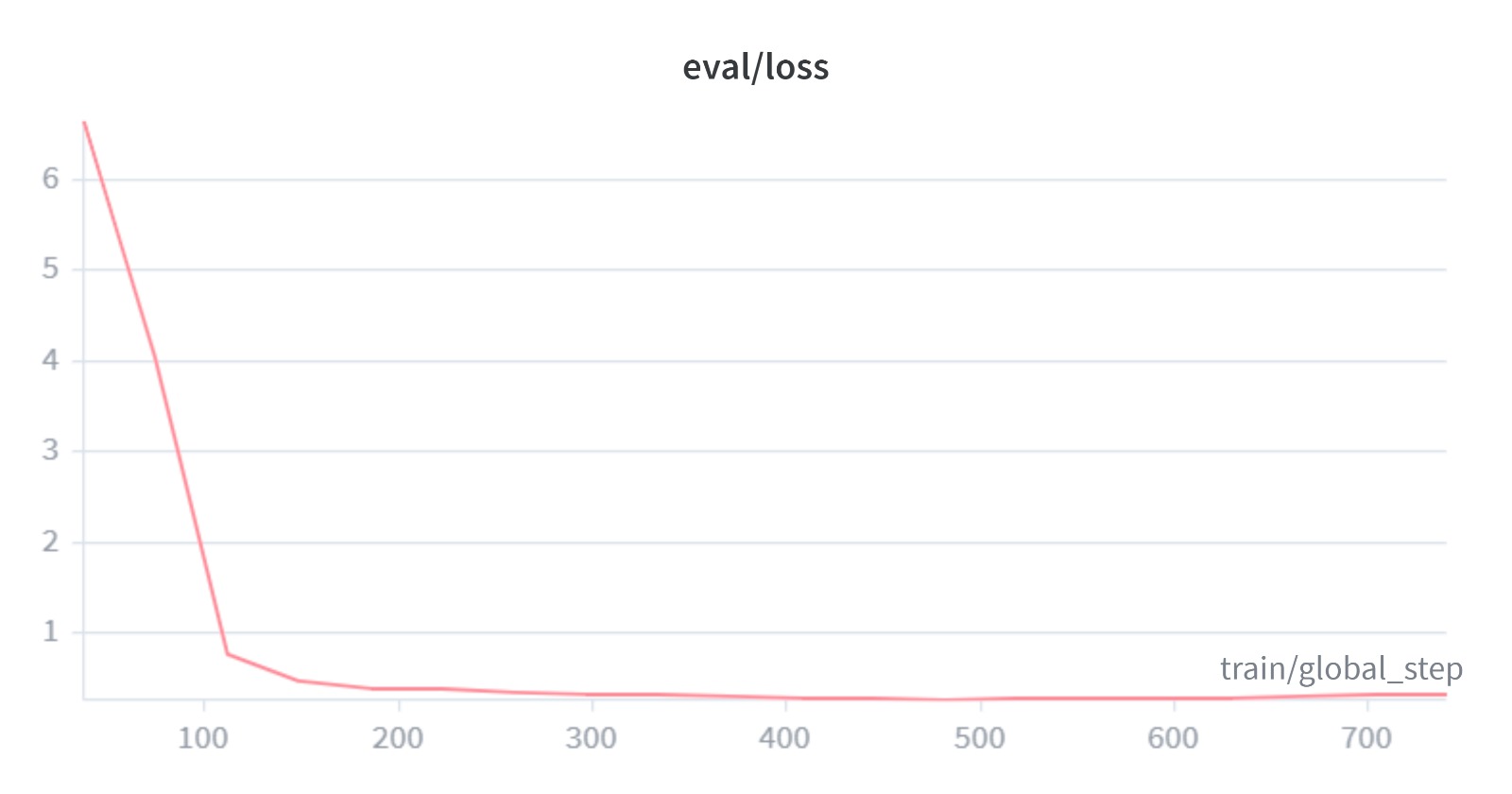
Training and Evaluation Curves
Qualitative Results
The following examples demonstrate predictions generated by the fine-tuned TrOCR model on handwritten Arabic text-line images.

Conclusion and Future Work
This project demonstrates that fine-tuning TrOCR is highly effective for Arabic handwritten text-line recognition. The model achieved a CER of 8.10% and significantly outperformed the selected cross-attention Arabic handwritten recognition baseline.
Future work includes testing larger TrOCR variants, exploring stronger augmentation strategies, evaluating more Arabic handwriting datasets, and improving Arabic-specific language modeling.
References
- Minghao Li et al., TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models, 2022.
- Saleh Momeni and Bagher BabaAli, A Transformer-based Approach for Arabic Offline Handwritten Text Recognition, 2023.
- KHATT v1.0 Dataset.
- Hugging Face Transformers Library.
- PyTorch Deep Learning Framework.